Sequence ID Generator
In my past career, when making a service, the very first concern is about how to identify resources internally on server-side. Yes, I mean the ID for users, orders, articles or something with a key to retrive it. ID can be in various options, integer, string and raw bytes. For a small-sized application that don’t scale, an auto-increment integer column on RDMS is enough. When it comes to scaling, ID format and generation is particularly important. Not only it affects storage space, but also service communication efficiency.
There are many string-formatted GUID generation algorithms, like UUID, Snowflake, MongoID, xid. They all don’t require a central server. String-formatted GUID generation are alike in implementation based on the running environments. The prominent disadvantages are the long length and sorting(some are sortable in ascii order).
| Algorithm | Bytes | String Length | Sortable |
|---|---|---|---|
16 | 36 | No | |
8 | Up to 19 | Yes | |
12 | 24 | Ascii order | |
12 | 20 | Ascii order |
As the name GUID implies, it is globally unique. In many scenarios, ID should be internally unique. e.g. message in group chat, message in user notification list. This is where sequence id comes in.
Small size. 32 bit or 64 bit integer.
Internally unique in session.
Sequential, keep increasing.
Preserve time-ordering.
Database auto-incrementing column used to generate sequential id, but it’s not scalable. In PostgreSQL, there is a built-in sequence generator. A new sequence generator means a new single-row table. When you have a lot of generators, for one million, maintaining database becomes the bottleneck. I don’t think that supports a large number of generators, let alone scaling.
Sequence ID to system is like Beavers to ecosystem, the infrastructure that make resources available that wouldn’t be otherwise.

1. General Approach
In a large system, ID generation need to be fast enough to handle request rate of the system. High request rate means high concurrency. So resource contention must be involved.
See the illustration of request processing from the perspective of server.
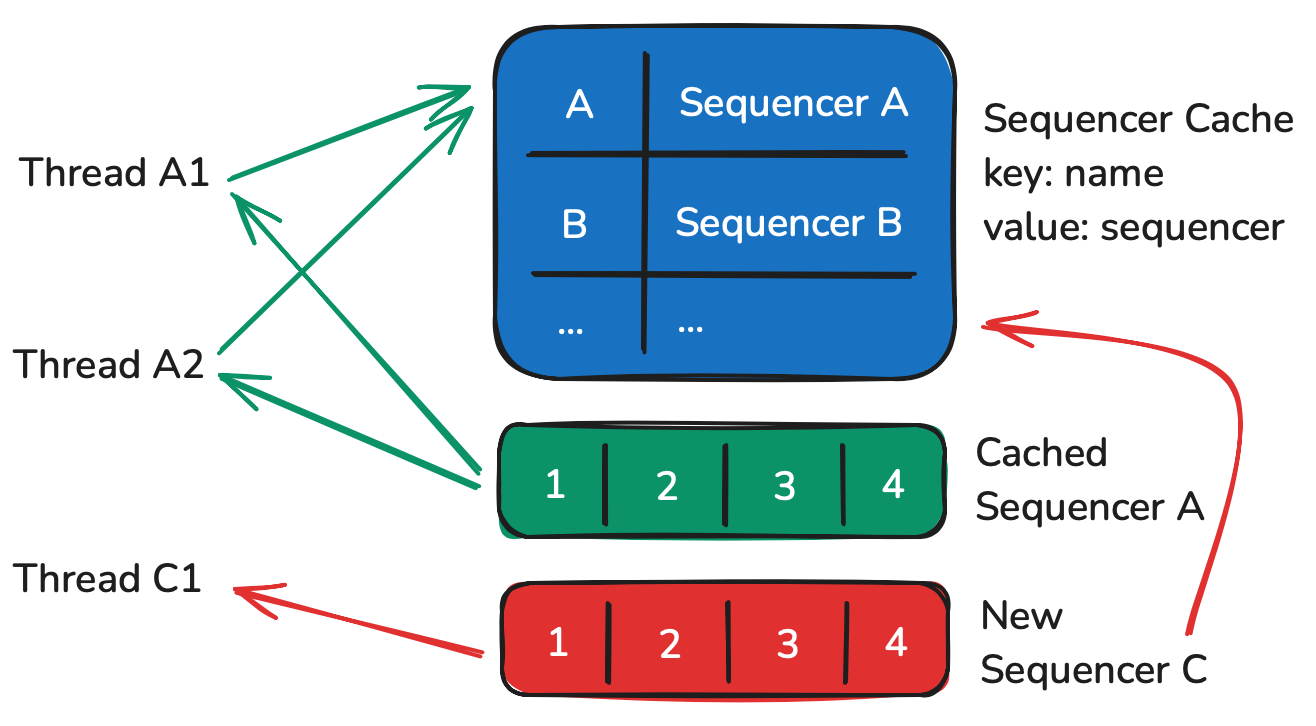
A request which queries the next available value in the sequence with a given name, when it comes, the server first need to check the cache with the give sequencer name. If there is a corresponding sequencer in the cache, then get the sequencer. This is a check-then-get operation. Reading a shared resource from multi-thread doesn’t involve contention. If there is not, create a new one with the given sequencer name, then add it to the cache. This is a check-then-set operation, and it requires mutual exclusion lock.
After get the sequencer, Read the next available value from the sequencer, and respond to request caller with the value.
Mutex lock is fine as it is only introduced on the first time new sequencer being created. If I can make sure only one thread execute check-then-set operation, then Mutex lock can be avoided completely.
2. Lock-free Design
In recent years, many programming languages introduced a new concurrency design pattern called coroutine. Like Kotlin and Golang. In companion with coroutine, channel is simple way for communication between coroutines. Channel allows to share information by communication rather than by a common mutable state. With this in mind, lock-free implementation becomes possible.
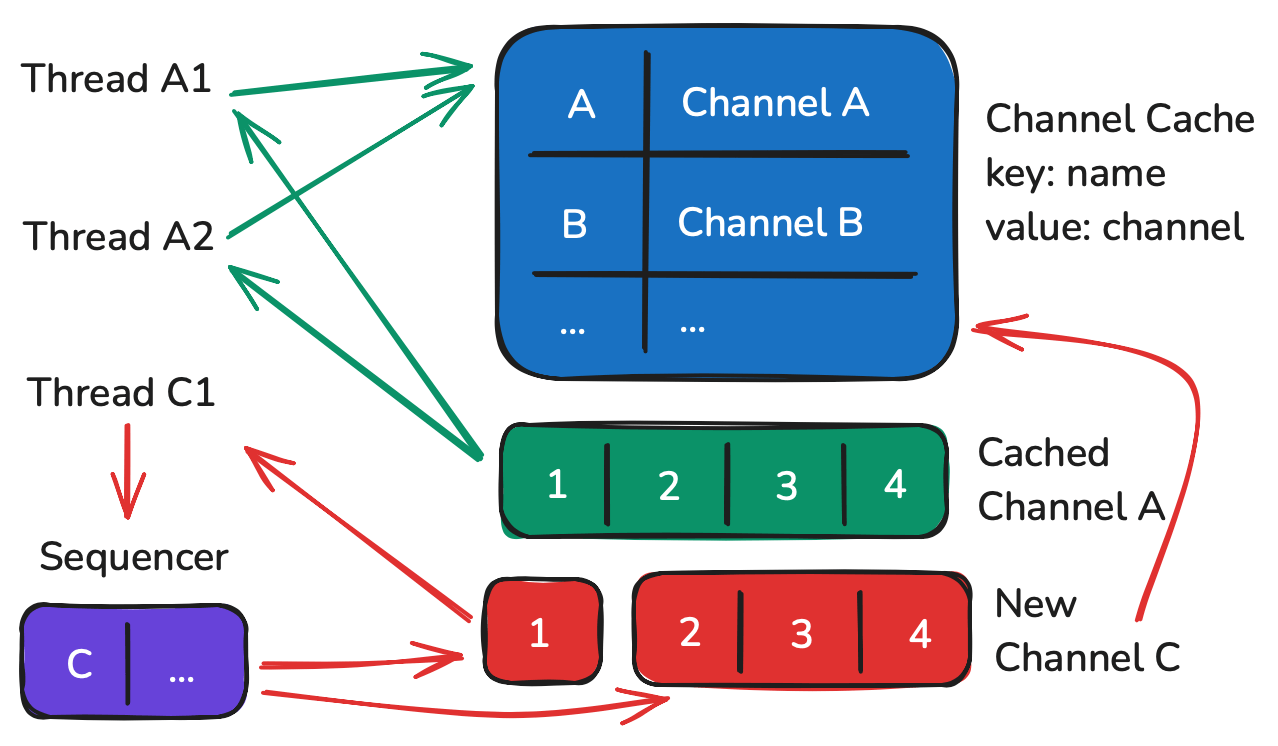
Like the processing in general approach, there is also a cache. But instead of caching sequencer, it caches channel. When a request comes, it first fetch the channel from the cache. If failed to fetch, it asks sequencer to create the channel. Along with that, create a temporary channel and wait for receiving.
The sequencer is like event stream consumer. It is responsible for creating sequence channel and caches it. After that send a value to the temporary channel the original request is waiting on.
There is a buffered channel the sequencer receive channel-creating element from it. It’s like event queue. The sequencer consumes from it. When asking sequencer for creating sequence channel, just send the sequence name along with a temporary channel to the queue. Then wait for receiving on the temporary channel.
Once the sequence channel created, subsequent request can just receive from the cached sequence channel. Until now, only the sequencer coroutine can update the cache, others read. So there is no Mutex lock required. This strategy improves performance further.
BeaverSeq is a high performance sequence ID generation service, implemented in Kotlin.
3. Distribution
For small-size application, a single node of such server is sufficient. Because you can have millions of coroutine in single machine. Coroutine is light-weight, it does not consume much RAM.
For large-scale application, a consistent hashing should be employed for sharding in front of server nodes. A single node can process millions of sequences.